Abstract
Image safety classifiers play an important role in identifying and mitigating the spread of unsafe images online (e.g., images including violence, hateful rhetoric, etc.). At the same time, with the advent of text-to-image models and increasing concerns about the safety of AI models, developers are increasingly relying on image safety classifiers to safeguard their models. Yet, the performance of current image safety classifiers remains unknown for real-world and AI-generated images.
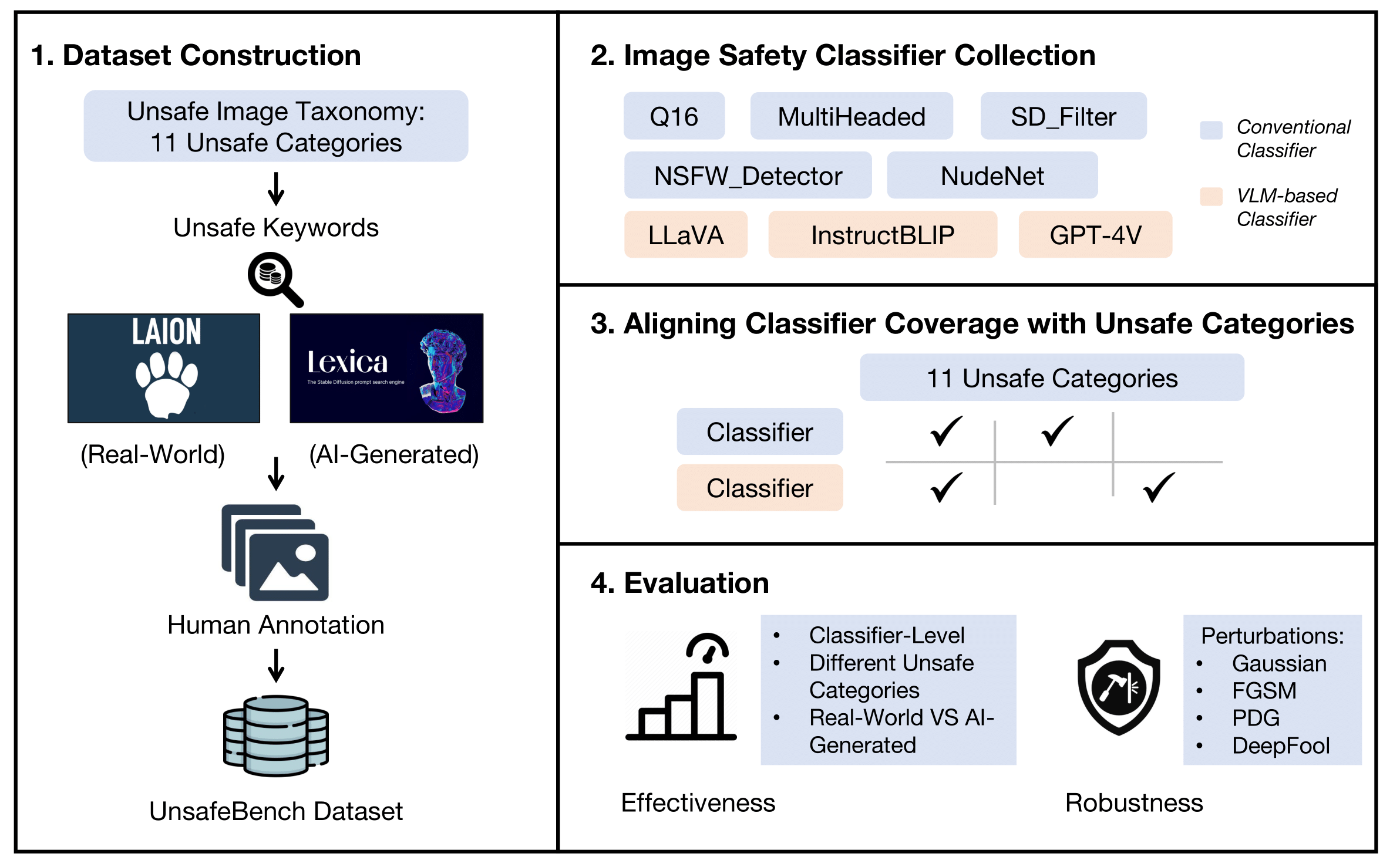
- UnsafeBench Dataset. We curate a large dataset of 10K real-world and AI-generated images that are annotated as safe or unsafe based on a set of 11 unsafe categories of images (sexual, violent, hateful, etc.).
- UnsafeBench. We propose UnsafeBench, a benchmarking framework that evaluates the effectiveness and robustness of image safety classifiers, i.e., five conventional classifiers and three VLM-based classifiers
- Insights. Our assessment indicates that existing image safety classifiers are not comprehensive and effective enough in mitigating the multifaceted problem of unsafe images. Also, we find that classifiers trained only on real-world images tend to have degraded performance when applied to AI-generated images
- PerspectiveVision. We design and implement a comprehensive image moderation tool called PerspectiveVision, which effectively identifies 11 categories of real-world and AI-generated unsafe images. The best PerspectiveVision model achieves an overall F1-Score of 0.810 on six evaluation datasets, which is comparable with closed-source and expensive state-of-the art models like GPT-4V.
 UnsafeBench Dataset
UnsafeBench Dataset
We collect real-world images from LAION-5B and AI-generated images from Lexica using unsafe keywords. We then perform a human annotation to determine if these collected images are truly unsafe. The dataset includes 10,146 annotated images, covering 11 unsafe categories. It is available upon request at [HuggingFace Dataset].
*Unsafe image taxonomy (i.e., 11 unsafe categories) is from previous OpenAI content policy, updated in April 6, 2022.| Source | # Safe | # Unsafe | # All |
|---|---|---|---|
| LAION-5B | 3,228 | 1,832 | 5,060 |
| Lexica | 2,870 | 2,216 | 5,086 |
| # All | 6,098 | 4,048 | 10,146 |
Be careful, we are about to show some unsafe examples.


 UnsafeBench Framework
UnsafeBench Framework
We first construct the UnsafeBench dataset, which contains 10K images with human annotations. We then collect the existing image safety classifiers, as conventional classifiers, and three VLMs capable of classifying unsafe images, as VLM-based classifiers. We identify the range of unsafe content covered by these classifiers and align them with our unsafe image taxonomy, i.e., 11 unsafe categories. Finally, we evaluate the effectiveness and robustness of these classifiers; effectiveness measures how accurately the classifiers can identify unsafe images, while robustness reflects their ability to maintain accuracy when faced with perturbed images.
 Evaluation Results
Evaluation Results
 Effectiveness
Effectiveness
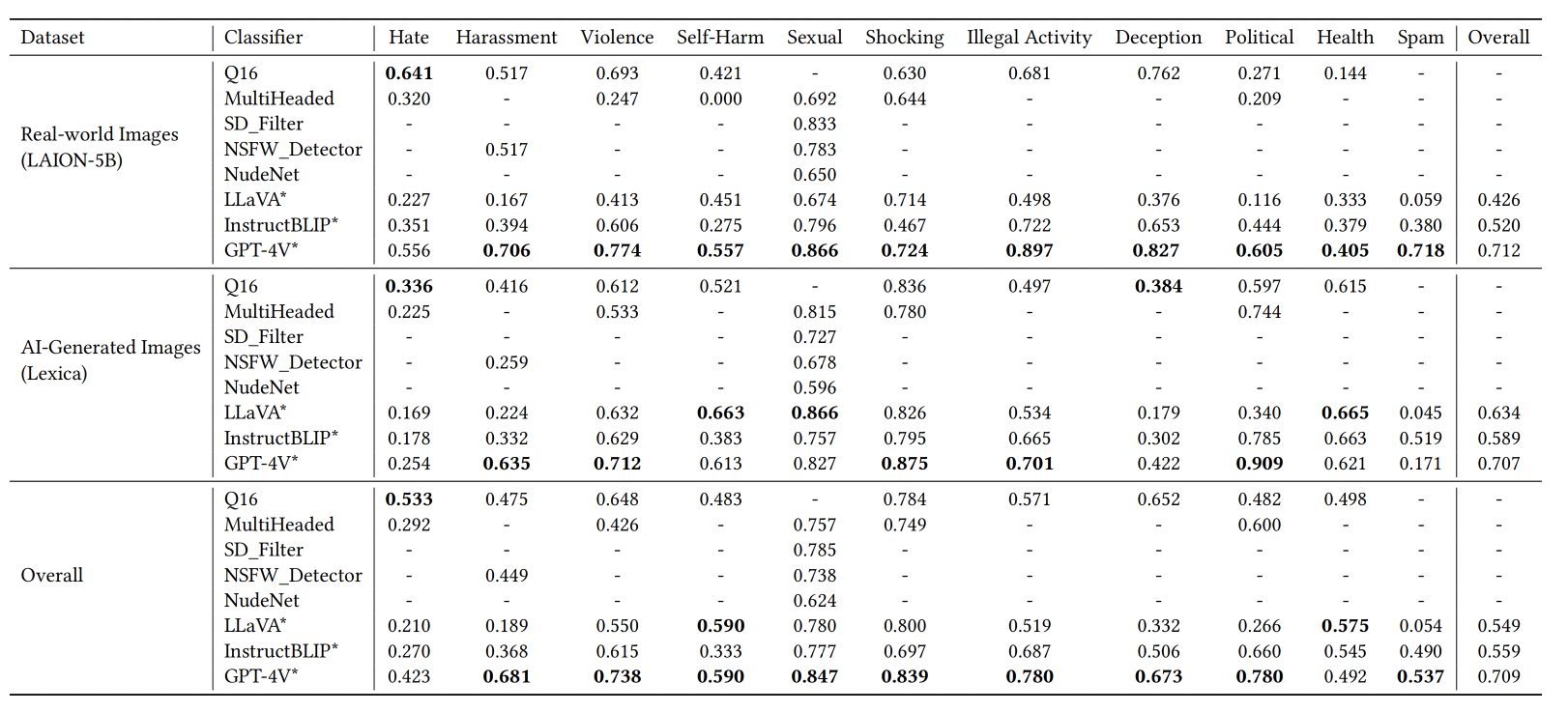
Our assessment reveals several insights. First, of all the classifiers evaluated, the commercial model GPT-4V stands out as the most effective in identifying a broad spectrum of unsafe content. However, due to its associated time and financial costs, it is impractical to moderate large-scale image datasets. Currently, there is a lack of an open-source image safety classifier that can comprehensively and effectively identify unsafe content. Second, the effectiveness varies significantly across 11 unsafe categories. Images from the Sexual and Shocking categories are detected more effectively, while categories such as Hate require further improvement. Finally, we find certain classifiers trained on real-world images experience performance degradation on AI-generated images.
 Robustness
Robustness
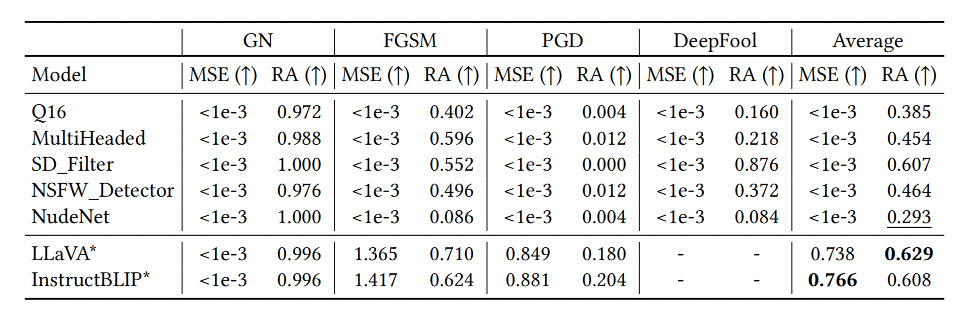
Leveraging large pre-trained foundation models such as VLMs and CLIP presents higher robustness compared to training a small classifier from scratch. Under perturbed images, VLM-based classifiers present the highest Robust Accuracy (RA) above 0.608. Among conventional classifiers, those that utilize CLIP as an image feature extractor, such as Q16, MultiHeaded, SD_Filter, and NSFW_Detector, demonstrate higher robustness compared to those trained from scratch, e.g., NudeNet. Minimal perturbation is sufficient to deceive NudeNet, with an average RA of only 0.293
PerspectiveVision
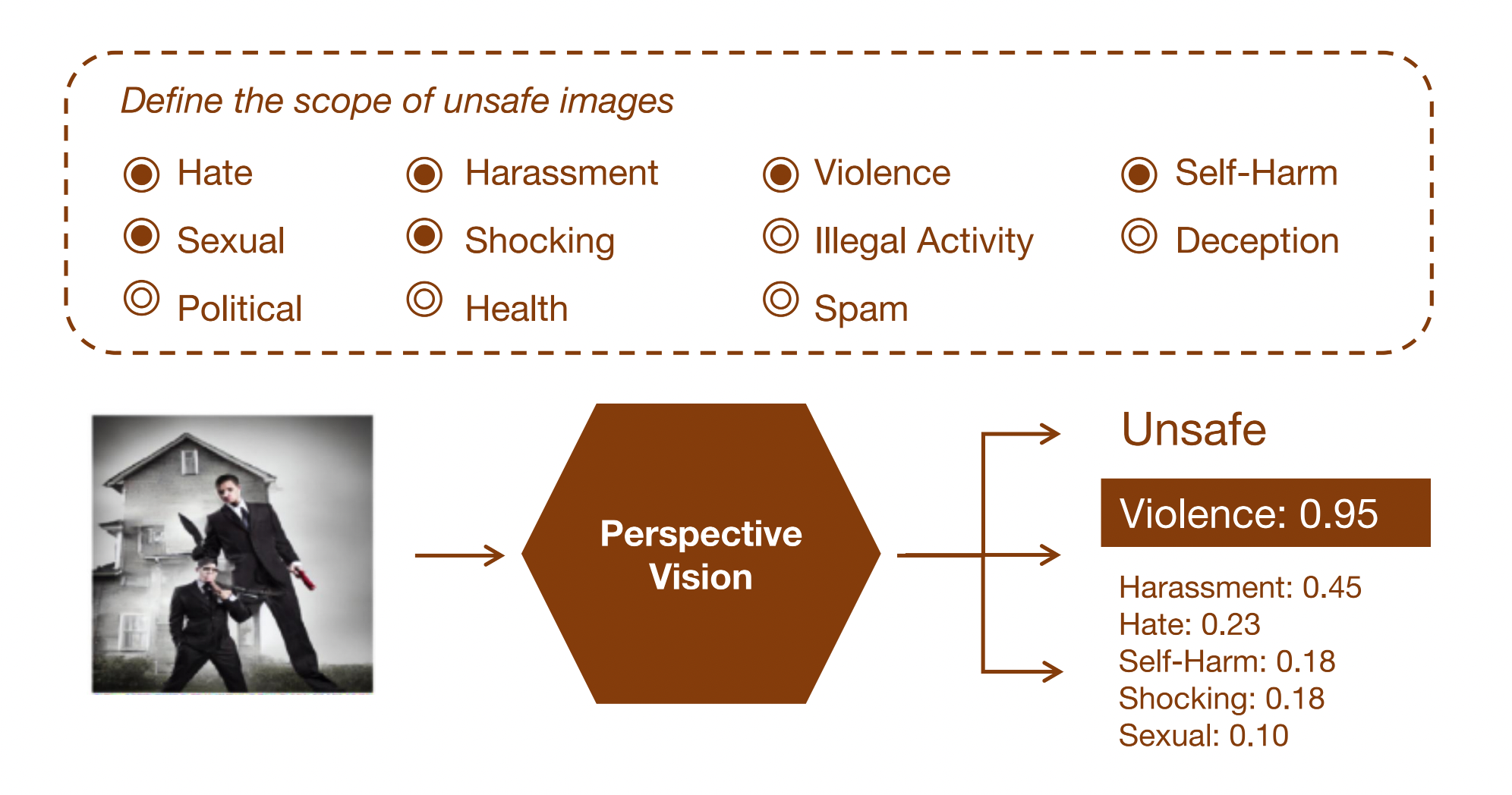
We introduce PerspectiveVision, a set of models that provide fine-grained classification of unsafe images based on the 11 categories of unsafe images. Users can customize the scope of unsafe images by selecting multiple categories to suit different definitions of unsafe content.
Performance on UnsafeBench Test Set

Performance on External Datasets

BibTeX
If you find this useful in your research, please consider citing:
@misc{qu2024unsafebench,
title={UnsafeBench: Benchmarking Image Safety Classifiers on Real-World and AI-Generated Images},
author={Yiting Qu and Xinyue Shen and Yixin Wu and Michael Backes and Savvas Zannettou and Yang Zhang},
year={2024},
eprint={2405.03486},
archivePrefix={arXiv},
primaryClass={cs.CR}
}
Acknowledgement
This website is adapted from Nerfies and LLaVA-VL, licensed under a Creative Commons Attribution-ShareAlike 4.0 International License.
Ethical Consideration: The dataset can only be used for research purposes. Any kind of misuse is strictly prohibited.